Let’s assume you have an application that runs happily on its own and is stateless. No problem. You deploy it onto Kubernetes and it works fine. You kill the pod and it respins, happily continuing where it left off.
Let’s add three replicas to the group. That also is fine, since its stateless.
Let’s now change that so that the application is now stateful and requires storage of where it is in between runs. So you pre-provision a disk using EBS and hook that up into the pods, and convert the deployment to a stateful set. Great, it still works fine. All three will pick up where they left off.
Now, what if we wanted to share the same state between the replicas?
For example, what if these three replicas were frontend boxes to a website? Having three different disks is a bad idea unless you can guarantee they will all have the same content. Even if you can, there’s guaranteed to be a case where one or more of the boxes will be either behind or ahead of the other boxes, and consequently have a case where one or more of the boxes will serve the wrong version of content.
There are several options for shared storage, NFS is the most logical but requires you to pre-provision a disk that will be used and also to either have an NFS server outside the cluster or create an NFS pod within the cluster. Also, you will likely over-provision your disk here (100GB when you only need 20GB for example)
Another alternative is EFS, which is Amazon’s NFS storage, where you mount an NFS and only pay for the amount of storage you use. However, even when creating a filesystem in a public subnet, you get a private IP which is useless if you are not DirectConnected into the VPC.
Another option is S3, but how do you use that short of using “s3 sync” repeatedly?
One answer is through the use of s3fs and sshfs
We use s3fs to mount the bucket into a pod (or pods), then we can use those mounts via sshfs as an NFS-like configuration.
The downside to this setup is the fact it will be slower than locally mounted disks.
So here’s the yaml for the s3fs pods (change values within {…} where applicable) — details at Docker Hub here: https://hub.docker.com/r/blenderfox/s3fs/
(and yes, I could convert the environment variables into secrets and reference those, and I might do a follow up article for that)
---
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: s3fs
namespace: default
labels:
k8s-app: s3fs
annotations: {}
spec:
replicas: 1
selector:
matchLabels:
k8s-app: s3fs
template:
metadata:
name: s3fs
labels:
k8s-app: s3fs
spec:
containers:
- name: s3fs
image: blenderfox/s3fs
env:
- name: S3_BUCKET
value: {...}
- name: S3_REGION
value: {...}
- name: AWSACCESSKEYID
value: {...}
- name: AWSSECRETACCESSKEY
value: {...}
- name: REMOTEKEY
value: {...}
- name: BUCKETUSERPASSWORD
value: {...}
resources: {}
imagePullPolicy: Always
securityContext:
privileged: true
restartPolicy: Always
terminationGracePeriodSeconds: 30
dnsPolicy: ClusterFirst
securityContext: {}
schedulerName: default-scheduler
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%
revisionHistoryLimit: 10
progressDeadlineSeconds: 600
---
kind: Service
apiVersion: v1
metadata:
name: s3-service
annotations:
external-dns.alpha.kubernetes.io/hostname: {hostnamehere}
service.beta.kubernetes.io/aws-load-balancer-connection-idle-timeout: "3600"
labels:
name: s3-service
spec:
ports:
- protocol: TCP
name: ssh
port: 22
targetPort: 22
selector:
k8s-app: s3fs
type: LoadBalancer
sessionAffinity: None
externalTrafficPolicy: Cluster
This will create a service and a pod
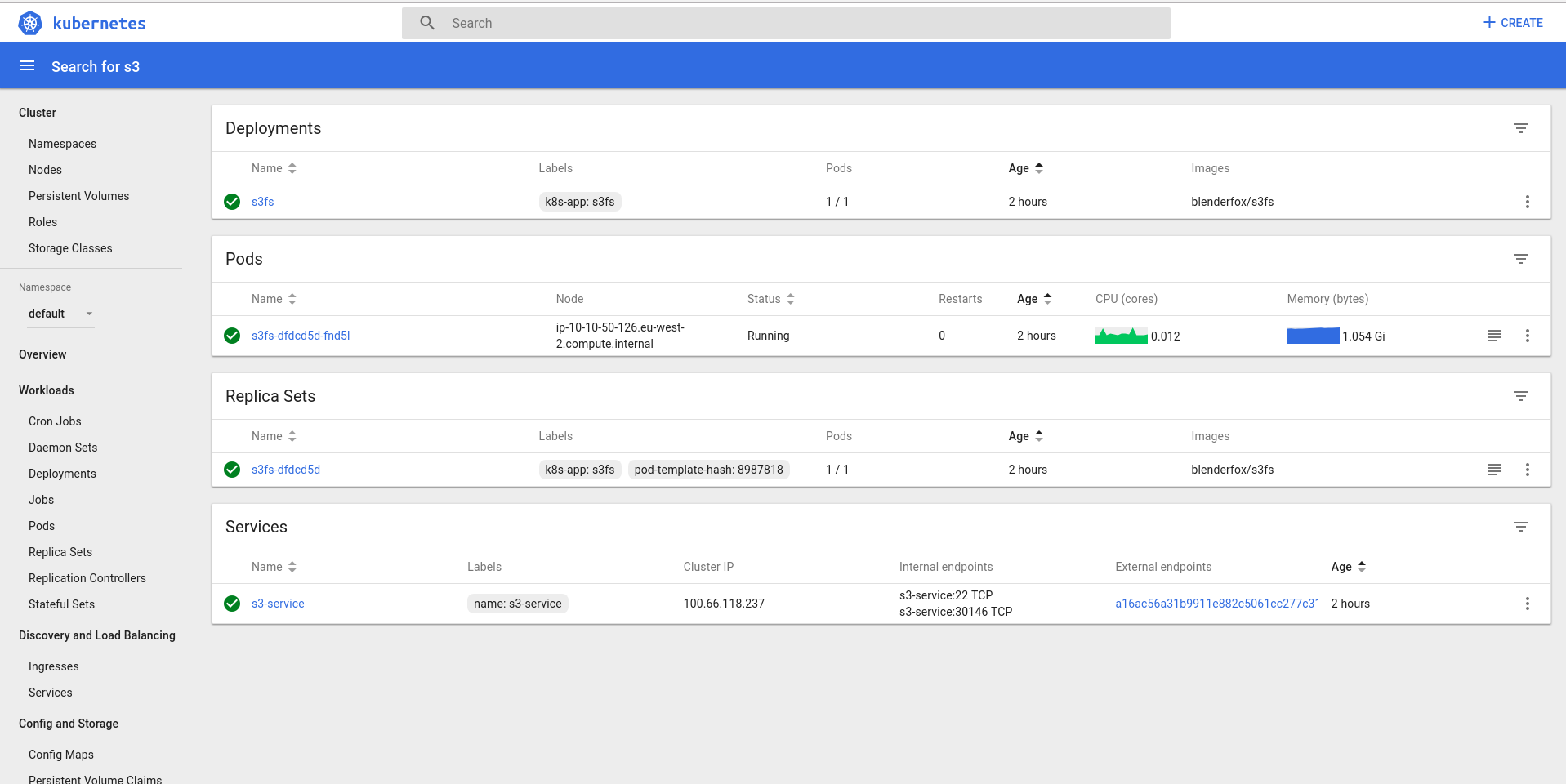
If you have external DNS enabled, the hostname will be added to Route 53.
SSH into the service and verify you can access the bucket mount
ssh bucketuser@dns-name ls -l /mnt/bucket/
(This should give you the listing of the bucket and also should have user:group set on the directory as “bucketuser”)
You should also be able to rsync into the bucket using this
rsync -rvhP /source/path bucketuser@dns-name:/mnt/bucket/
Or sshfs using a similar method
sshfs bucketuser@dns-name:/mnt/bucket/ /path/to/local/mountpoint
Edit the connection timeout annotation if needed
Now, if you set up a pod that has three replicas and all three sshfs to the same service, you essentially have an NFS-like storage.



You must be logged in to post a comment.