Exam
#Not long left till my exam so spending the last few hours just going through some review questions from Linux Academy
Not long left till my exam so spending the last few hours just going through some review questions from Linux Academy
While booking my CKA exam earlier, I spotted that there was a second Kubernetes certification – Certified Kubernetes Application Developer.
While the CKA is for the admin of the cluster and tests the knowledge of the infrastructure, CKAD is more for the developers.
Looks like that’ll be my next certification…
With less than 24 hours to go before my exam, I’m going to spend those last hours going through the review questions and see if I can still remember the content.
Right, my exam is booked. For tomorrow. :)

I’ve decided to take the plunge and for the Certified Kubernetes Administrator certification. Wish me luck! :)
There is a new story doing the round about how Twitter found that it had stored user’s password in the clear in an internal log. Whilst reading it, I got this email from Twitter:
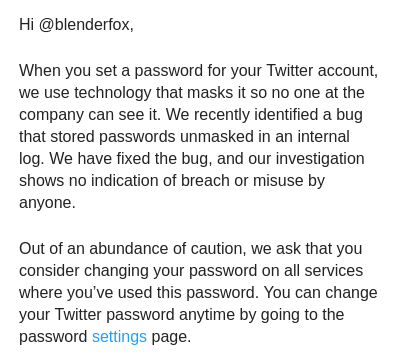
While this isn’t the first time a big company has done this (Github for one also did this), it seems unbelievable that a big company like Twitter would get itself caught out by this basic, common sense security practice. Pretty much every YouTube video and article about correctly handling passwords will tell you not to store them in the clear and only store them as hashes (with salts, preferably). Hashing algorithms are meant to be really difficult or impossible to reverse, meaning you can’t (easily) use the hashes to determine the original passwords.
Some examples from a quick YouTube search – Tom Scott’s video’s really good btw :), although is comment about “using login using Twitter and let them store your password for you” is a bit ironic :P
The fact that Twitter has our unencrypted passwords on disk… does this mean Twitter has been saving our original passwords before hashing them?
More to the point - whilst Twitter are quick to point out that no-one at the company can see the masked password, they don’t mention who has (or had) access to the unmasked passwords in the internal log. Or for how long…
Twitter users who had their accounts on private may not have been as private as they initially thought….
The Rancher guys have put out an intro training video of Kubernetes on Rancher 2.0 – give it a check if you have time. :)
So, I install Ubuntu 17 clean on my laptop after the issues I had with drivers and immediately found out that gksu was not installed.
Installed that and tried to
gksudo nautilus
That failed and found out that Wayland had replaced the default of Xorg. Found an old Xauthority file from my backups and copied that back, which allowed me to get the popup window back for my gksu, but I couldn’t click it to enter the password :(
Then I found this article:
https://www.linuxuprising.com/2018/04/gksu-removed-from-ubuntu-heres.html
Which tells me I need to use the admin:/// file prefix instead to open something up as admin. Guess I’ll give it a go later.
There’s a thought experiment known as Theseus’s paradox (and a couple of variants) and it goes something like this.
If you have a raft and replace the oars and planks due to them rotting or being old, or similar, to such a level that the entire raft is eventually replaced, is it still the same ship?
If you inherited an axe from your uncle and you replace the axe head because it’s blunt, and then the wooden handle because it broke – is that axe still the same one you inherited? Can you still call it your uncle’s axe?
Similarly, if all parts of a computer program are replaced by patches/hotfixes (not as full releases), is it still the same program? Can you, for example, call Microsoft Excel V1 a V1 if every part of it has been replaced with new code through patches and hotfixes? Can you even call it Microsoft Excel?

This is not going to end well….
(Source: www.commitstrip.com/en/2018/0…)

A quick note to remind myself (and other people) how to tunnel to a node (or pod) in Kubernetes via the bastion server
[code lang=text] rm ~/.ssh/known_hosts #Needed if you keep scaling the bastion up/down
BASTION=bastion.{cluster-domain} DEST=$1
ssh -o StrictHostKeyChecking=no -o ProxyCommand=‘ssh -o StrictHostKeyChecking=no -W %h:%p admin@bastion.{cluster-domain}’ admin@$DEST [/code]
Run like this:
[code lang=text] bash ./tunnelK8s.sh NODE_IP [/code]
Example:
[code lang=text] bash ./tunnelK8s.sh 10.10.10.100 #Assuming 10.10.10.100 is the node you want to connect to. [/code]
You can extend this by using this to ssh into a pod, assuming the pod has an SSH server on it.
[code lang=text] BASTION=bastion.${cluster domain name} NODE=$1 NODEPORT=$2 PODUSER=$3
ssh -o ProxyCommand=“ssh -W %h:%p admin@$BASTION” admin@$NODE ssh -tto StrictHostKeyChecking=no $PODUSER@localhost -p $NODEPORT [/code]
So if you have service listening on port 32000 on node 10.10.10.100 that expects a login user of “poduser”, you would do this:
[code lang=text] bash ./tunnelPod.sh 10.10.10.100 32000 poduser [/code]
If you have to pass a password you can install sshpass on the node, then use that (be aware of security risk though - this is not an ideal solution)
[code lang=text] ssh -o ProxyCommand=“ssh -W %h:%p admin@$BASTION” admin@$NODE sshpass -p ${password} ssh -tto StrictHostKeyChecking=no $PODUSER@localhost -p $NODEPORT [/code]
Caveat though – you will have to make sure that your node security group allows your bastion security group to talk to the nodes on the additional ports. By default, the only port that the bastions are able to talk to the node security groups on is SSH (22) only.
Facebook have been having a lot of bad publicity lately (and I would personally say it’s long overdue) and a lot of it over privacy. Now, there’s talk about Facebook lifting SMS and phone call information from Android phones with consent. Yes, Facebook asks for it, but you can (and should) refuse it access.
Later versions of Android allow you to revoke and change the permissions given to an app, and also prompt you again if the app asks for it.
My Facebook app has very little permissions on my device because I don’t trust it a single bit.

I also have Privacy Guard enabled and restricted. Whenever it wants to know my location, I can refuse it.

SONOMA, Calif., March 6, 2018 – Open Source Leadership Summit – The Cloud Native Computing Foundation® (CNCF®), which sustains and integrates open source technologies like Kubernetes® and Prometheus™, today announced that Kubernetes is the first project to graduate. To move from incubation to graduate, projects must demonstrate thriving adoption, a documented, structured governance process, and a strong commitment to community success and inclusivity.
Great news :) shows that Kubernetes is now considered more mature than previously and it definitely shows.
Let’s assume you have an application that runs happily on its own and is stateless. No problem. You deploy it onto Kubernetes and it works fine. You kill the pod and it respins, happily continuing where it left off.
Let’s add three replicas to the group. That also is fine, since its stateless.
Let’s now change that so that the application is now stateful and requires storage of where it is in between runs. So you pre-provision a disk using EBS and hook that up into the pods, and convert the deployment to a stateful set. Great, it still works fine. All three will pick up where they left off.
Now, what if we wanted to share the same state between the replicas?
For example, what if these three replicas were frontend boxes to a website? Having three different disks is a bad idea unless you can guarantee they will all have the same content. Even if you can, there’s guaranteed to be a case where one or more of the boxes will be either behind or ahead of the other boxes, and consequently have a case where one or more of the boxes will serve the wrong version of content.
There are several options for shared storage, NFS is the most logical but requires you to pre-provision a disk that will be used and also to either have an NFS server outside the cluster or create an NFS pod within the cluster. Also, you will likely over-provision your disk here (100GB when you only need 20GB for example)
Another alternative is EFS, which is Amazon’s NFS storage, where you mount an NFS and only pay for the amount of storage you use. However, even when creating a filesystem in a public subnet, you get a private IP which is useless if you are not DirectConnected into the VPC.
Another option is S3, but how do you use that short of using “s3 sync” repeatedly?
One answer is through the use of s3fs and sshfs
We use s3fs to mount the bucket into a pod (or pods), then we can use those mounts via sshfs as an NFS-like configuration.
The downside to this setup is the fact it will be slower than locally mounted disks.
So here’s the yaml for the s3fs pods (change values within {…} where applicable) – details at Docker Hub here: https://hub.docker.com/r/blenderfox/s3fs/
(and yes, I could convert the environment variables into secrets and reference those, and I might do a follow up article for that)
kind: Service apiVersion: v1 metadata: name: s3-service annotations: external-dns.alpha.kubernetes.io/hostname: {hostnamehere} service.beta.kubernetes.io/aws-load-balancer-connection-idle-timeout: “3600” labels: name: s3-service spec: ports:
[/code]
This will create a service and a pod

If you have external DNS enabled, the hostname will be added to Route 53.
SSH into the service and verify you can access the bucket mount
[code] ssh bucketuser@dns-name ls -l /mnt/bucket/ [/code]
(This should give you the listing of the bucket and also should have user:group set on the directory as “bucketuser”)
You should also be able to rsync into the bucket using this
[code] rsync -rvhP /source/path bucketuser@dns-name:/mnt/bucket/ [/code]
Or sshfs using a similar method
[code]
sshfs bucketuser@dns-name:/mnt/bucket/ /path/to/local/mountpoint
[/code]
Edit the connection timeout annotation if needed
Now, if you set up a pod that has three replicas and all three sshfs to the same service, you essentially have an NFS-like storage.
Whilst finding vulnerabilities is a bad thing, having them found by white hat hackers is a good thing. Hackathons like this one prove that it can be constructive to get a group of them in to find and help fix vulnerabilities in your system before they are found in public and exploited to death before you have a chance to fix them.
The US Air Force's second security hackathon has paid dividends... both for the military and the people finding holes in its defenses. HackerOne has revealed the results of the Hack the Air Force 2.0 challenge from the end of 2017, and it led to volunteers discovering 106 vulnerabilities across roughly 300 of the USAF's public websites. Those discoveries proved costly, however. The Air Force paid out a total of $103,883, including $12,500 for one bug -- the most money any federal bounty program has paid to date.
Having a master in a Kubernetes cluster is all very well and good, but if that master goes down the entire cluster cannot schedule new work. Pods will continue to run, but new ones cannot be scheduled and any pods that die will not get rescheduled.
Having multiple masters allows for more resiliency and can pick up when one goes down. However, as I found out, setting multi-master was quite problematic. Using the guide here only provided some help so after trashing my own and my company’s test cluster, I have expanded on the linked guide.
First add the subnet details for the new zone into your cluster definition – CIDR, subnet id, and make sure you name it something that you can remember. For simplicity, I called mine eu-west-2c. If you have a definition for utility (and you will if you use a bastion), make sure you have a utility subnet also defined for the new AZ
[code lang=shell] kops edit cluster –state s3://bucket [/code]
Now, create your master instance groups, you need an odd number to enable quorum and avoid split brain (I’m not saying prevent, and there are edge cases where this could be possible even with quorum). I’m going to add west-2b and west-2c. AWS recently introduced the third London AWS zone, so I’m going to use that.
[code lang=shell] kops create instancegroup master-eu-west-2b –subnet eu-west-2b –role Master [/code]
Make this one have a max/min of 1
[code lang=shell] kops create instancegroup master-eu-west-2c –subnet eu-west-2c –role Master [/code]
Make this one have a max/min of 0 (yes, zero) for now
Reference these in your cluster config
[code lang=text] kops edit cluster –state=s3://bucket [/code]
[code lang=text] etcdClusters:
Start the new master
[code lang=shell] kops update cluster –state s3://bucket –yes [/code]
Find the etcd and etcd-event pods and add them to this script. Change “clustername” to the name of your cluster, then run it. Confirm the member lists include both two members (in my case it would be etc-a and etc-b)
[code lang=shell] ETCPOD=etcd-server-events-ip-10-10-10-226.eu-west-2.compute.internal ETCEVENTSPOD=etcd-server-ip-10-10-10-226.eu-west-2.compute.internal AZ=b CLUSTER=clustername
kubectl –namespace=kube-system exec $ETCPOD – etcdctl member add etcd-$AZ http://etcd-$AZ.internal.$CLUSTER:2380
kubectl –namespace=kube-system exec $ETCEVENTSPOD – etcdctl –endpoint http://127.0.0.1:4002 member add etcd-events-$AZ http://etcd-events-$AZ.internal.$CLUSTER:2381
echo Member Lists kubectl –namespace=kube-system exec $ETCPOD – etcdctl member list
kubectl –namespace=kube-system exec $ETCEVENTSPOD – etcdctl –endpoint http://127.0.0.1:4002 member list [/code]
(NOTE: the cluster will break at this point due to the missing second cluster member)
Wait for the master to show as initialised. Find the instance id of the master and put it into this script. Change the AWSSWITCHES to match any switches you need to provide to the awscli. For me, I specify my profile and region
The script will run and output the status of the instance until it shows “ok”
[code lang=shell] AWSSWITCHES="–profile personal –region eu-west-2" INSTANCEID=master2instanceid while [ “$(aws $AWSSWITCHES ec2 describe-instance-status –instance-id=$INSTANCEID –output text | grep SYSTEMSTATUS | cut -f 2)” != “ok” ] do sleep 5s aws $AWSSWITCHES ec2 describe-instance-status –instance-id=$INSTANCEID –output text | grep SYSTEMSTATUS | cut -f 2 done aws $AWSSWITCHES ec2 describe-instance-status –instance-id=$INSTANCEID –output text | grep SYSTEMSTATUS | cut -f 2 [/code]
ssh into the new master (or via bastion if needed)
[code lang=shell] sudo -i systemctl stop kubelet systemctl stop protokube [/code]
edit /etc/kubernetes/manifests/etcd.manifest and /etc/kubernetes/manifests/etcd-events.manifest
Change the ETCD_INITIAL_CLUSTER_STATE value from new to existing
Under ETCD_INITIAL_CLUSTER remove the third master definition
Stop the etcd docker containers
[code lang=shell] docker stop $(docker ps | grep “etcd” | awk ‘{print $1}') [/code]
Run this a few times until you get a docker error saying you need more than one container name There are two volumes mounted under /mnt/master-vol-xxxxxxxx, one contains /var/etcd/data-events/member/ and one contains /var/etcd/data/member/ but it varies because of the id.
[code lang=shell] rm -r /mnt/var/master-vol-xxxxxx/var/etcd/data-events/member/ rm -r /mnt/var/master-vol-xxxxxx/var/etcd/data/member/ [/code]
Now start kubelet
[code lang=shell] systemctl start kubelet [/code]
Wait until the master shows on the validate list then start protokube
[code lang=shell] systemctl start protokube [/code]
Now do the same with the third master
edit the third master ig to make it min/max 1
[code lang=shell] kops edit ig master-eu-west-2c –name=clustername –state s3://bucket [/code]
Add it to the clusters (the etcd pods should still be running)
[code lang=shell] ETCPOD=etcd-server-events-ip-10-10-10-226.eu-west-2.compute.internal ETCEVENTSPOD=etcd-server-ip-10-10-10-226.eu-west-2.compute.internal AZ=c CLUSTER=clustername
kubectl –namespace=kube-system exec $ETCPOD – etcdctl member add etcd-$AZ http://etcd-$AZ.internal.$CLUSTER:2380 kubectl –namespace=kube-system exec $ETCEVENTSPOD – etcdctl –endpoint http://127.0.0.1:4002 member add etcd-events-$AZ http://etcd-events-$AZ.internal.$CLUSTER:2381
echo Member Lists kubectl –namespace=kube-system exec $ETCPOD – etcdctl member list kubectl –namespace=kube-system exec $ETCEVENTSPOD – etcdctl –endpoint http://127.0.0.1:4002 member list
[/code]
Start the third master
[code lang=shell] kops update cluster –name=cluster-name –state=s3://bucket [/code]
Wait for the master to show as initialised. Find the instance id of the master and put it into this script. Change the AWSSWITCHES to match any switches you need to provide to the awscli. For me, I specify my profile and region
The script will run and output the status of the instance until it shows “ok”
[code lang=shell] AWSSWITCHES="–profile personal –region eu-west-2" INSTANCEID=master3instanceid while [ “$(aws $AWSSWITCHES ec2 describe-instance-status –instance-id=$INSTANCEID –output text | grep SYSTEMSTATUS | cut -f 2)” != “ok” ] do sleep 5s aws $AWSSWITCHES ec2 describe-instance-status –instance-id=$INSTANCEID –output text | grep SYSTEMSTATUS | cut -f 2 done aws $AWSSWITCHES ec2 describe-instance-status –instance-id=$INSTANCEID –output text | grep SYSTEMSTATUS | cut -f 2 [/code]
ssh into the new master (or via bastion if needed)
[code lang=shell] sudo -i systemctl stop kubelet systemctl stop protokube [/code]
edit /etc/kubernetes/manifests/etcd.manifest and /etc/kubernetes/manifests/etcd-events.manifest
Change the ETCD_INITIAL_CLUSTER_STATE value from new to existing
We DON’T need to remove the third master defintion this time, since this is the third master
Stop the etcd docker containers
[code lang=shell] docker stop $(docker ps | grep “etcd” | awk ‘{print $1}') [/code]
Run this a few times until you get a docker error saying you need more than one container name There are two volumes mounted under /mnt/master-vol-xxxxxxxx, one contains /var/etcd/data-events/member/ and one contains /var/etcd/data/member/ but it varies because of the id.
[code lang=shell] rm -r /mnt/var/master-vol-xxxxxx/var/etcd/data-events/member/ rm -r /mnt/var/master-vol-xxxxxx/var/etcd/data/member/ [/code]
Now start kubelet
[code lang=shell] systemctl start kubelet [/code]
Wait until the master shows on the validate list then start protokube
[code lang=shell] systemctl start protokube [/code]
If the cluster validates, do a full respin
[code lang=shell] kops rolling-update cluster –name clustername –state s3://bucket –force –yes [/code]
Kubernetes is an awesome piece of kit, you can set applications to run within the cluster, make it visible to only apps within the cluster and/or expose it to applications outside of the cluster.
As part of my tinkering, I wanted to setup a Docker Registry to store my own images without having to make them public via docker hub. Doing this proved a bit more complicated than expected since by default, it requires SSL which requires a certificate to be purchased and installed.
Enter Let’s Encrypt which allows you to get SSL certificates for free; and by using their API, you can set it to regularly renew. Kubernetes has the kube-lego project which allows this regular integration. So here, I’ll go through enabling an application (in this case, it’s a docker registry, but it can be anything).
First, lets ignore the lego project, and set up the application so that it is accessible normally. As mentioned above, this is the docker registry
I’m tying the registry storage to a pv claim, though you can modify this to tie to S3, instead etc.
kind: Service apiVersion: v1 metadata: name: registry namespace: default labels: name: registry spec: ports:
[/code]
Once you’ve applied this, verify your config is correct by ensuring you have an external endpoint for the service (use kubectl describe service registry | grep “LoadBalancer Ingress”). On AWS, this will be an ELB, on other clouds, you might get an IP. If you get an ELB, CNAME a friendly name to it. If you get an IP, create an A record for it. I’m going to use registry.blenderfox.com for this test.
Verify by doing this. Bear in mind it can take a while before DNS records updates so be patient.
host $(SERVICE_DNS)
So if I had set the service to be registry.blenderfox.com, I would do
host registry.blenderfox.com
If done correctly, this should resolve to the ELB then resolve to the ELB IP addresses.
Next, try to tag a docker image of the format registry-host:port/imagename, so, for example, registry.blenderfox.com:9000/my-image.
Next try to push it.
docker push registry.blenderfox.com:9000/my-image
It will fail because it can’t talk over https
docker push registry.blenderfox.com:9000/my-image The push refers to repository [registry.blenderfox.com:9000/my-image] Get https://registry.blenderfox.com:9000/v2/: http: server gave HTTP response to HTTPS client
So let’s now fix that.
Now let’s start setting up kube-lego
Checkout the code
git clone git@github.com:jetstack/kube-lego.git
cd into the relevant folder
cd kube-lego/examples/nginx
Start applying the code base
[code lang=text] kubectl apply -f lego/00-namespace.yaml kubectl apply -f nginx/00-namespace.yaml kubectl apply -f nginx/default-deployment.yaml kubectl apply -f nginx/default-service.yaml [/code]
Open up nginx/configmap.yaml and change the body-size: “64m” line to a bigger value. This is the maximum size you can upload through nginx. You’ll see why this is an important change later.
[code lang=text] kubectl apply -f nginx/configmap.yaml kubectl apply -f nginx/service.yaml kubectl apply -f nginx/deployment.yaml [/code]
Now, look for the external endpoint for the nginx service
kubectl describe service nginx -n nginx-ingress | grep “LoadBalancer Ingress”
Look for the value next to LoadBalancer Ingress. On AWS, this will be the ELB address.
CNAME your domain for your service (e.g. registry.blenderfox.com in this example) to that ELB. If you’re not on AWS, this may be an IP, in which case, just create an A record instead.
Open up lego/configmap.yaml and change the email address in there to be the one you want to use to request the certs.
[code lang=text] kubectl apply -f lego/configmap.yaml kubectl apply -f lego/deployment.yaml [/code]
Wait for the DNS to update before proceeding to the next step.
host registry.blenderfox.com
When the DNS is updated, finally create and add an ingress rule for your service:
kind: Ingress apiVersion: extensions/v1beta1 metadata: name: registry namespace: default annotations: kubernetes.io/ingress.class: nginx kubernetes.io/tls-acme: ‘true’ spec: tls:
Look add the logs in nginx-ingress/nginx and you’ll see the Let’s Encrypt server come in to validate:
100.124.0.0 - [100.124.0.0] - - [19/Jan/2018:09:50:19 +0000] "GET /.well-known/acme-challenge/[REDACTED] HTTP/1.1" 200 87 "-" "Mozilla/5.0 (compatible; Let's Encrypt validation server; +https://www.letsencrypt.org)" 277 0.044 100.96.0.3:8080 87 0.044 200
And look in the logs on the kube-lego/kube-lego pod and you’ll see the success and saving of the secret
time="2018-01-19T09:49:45Z" level=info msg="requesting certificate for registry.blenderfox.com" context="ingress_tls" name=registry namespace=default time="2018-01-19T09:50:21Z" level=info msg="authorization successful" context=acme domain=registry.blenderfox.com time="2018-01-19T09:50:47Z" level=info msg="successfully got certificate: domains=[registry.blenderfox.com] url=https://acme-v01.api.letsencrypt.org/acme/cert/[REDACTED]" context=acme time="2018-01-19T09:50:47Z" level=info msg="Attempting to create new secret" context=secret name=registry-tls namespace=default time="2018-01-19T09:50:47Z" level=info msg="Secret successfully stored" context=secret name=registry-tls namespace=default
Now let’s do a quick verify:
curl -ILv https://registry.blenderfox.com ... * Server certificate: * subject: CN=registry.blenderfox.com * start date: Jan 19 08:50:46 2018 GMT * expire date: Apr 19 08:50:46 2018 GMT * subjectAltName: host "registry.blenderfox.com" matched cert's "registry.blenderfox.com" * issuer: C=US; O=Let's Encrypt; CN=Let's Encrypt Authority X3 * SSL certificate verify ok. ...
That looks good.
Now let’s re-tag and try to push our image
docker tag registry.blenderfox.com:9000/my-image registry.blenderfox.com/my-image docker push registry.blenderfox.com/my-image
Note we are not using a port this time as there is now support for SSL.
BOOM! Success.
The tls section indicates the host to request the cert on, and the backend section indicates which backend to pass the request onto. The body-size config is at the nginx level so if you don’t change it, you can only upload a maximum of 64m even if the backend service (docker registry in this case) can support it. I have it set here at “1g” so I can upload 1gb (some docker images can be pretty large)
From the Kubernetes blog, the next version of Kubernetes has been released. And one feature has definitely caught my eye:
Windows Support (beta)Kubernetes was originally developed for Linux systems, but as our users are realizing the benefits of container orchestration at scale, we are seeing demand for Kubernetes to run Windows workloads. Work to support Windows Server in Kubernetes began in earnest about 12 months ago. SIG-Windows has now promoted this feature to beta status, which means that we can evaluate it for usage.
So users of Windows can now hook up Windows boxes into their cluster. Which leads to an interesting case of mixed-OS clusters. Strictly speaking, that’s already possible now with a mix of Linux distributions able to run Kubernetes.
Kubernetes confusing you? This is a really nice short video explaining the basic concepts of Kubernetes
You are always lectured about making backups of your systems, even more so when you are running archives from a very active mailing list. ^_^
This article is a guide on how to setup a Kubernetes cluster in AWS using kops and plugging it into your own subnets and VPC. We attempt to minimise the external IPs used in this method.
Export your AWS API keys into environment variables
[code lang=text] export AWS_ACCESS_KEY_ID=‘YOUR_KEY’ export AWS_SECRET_ACCESS_KEY=‘YOUR_ACCESS_KEY’ export CLUSTER_NAME=“my-cluster-name” export VPC=“vpc-xxxxxx” export K8SSTATE=“s3-k8sstate”</pre> [/code]
Create the cluster (you can change some of these switches to match your requirements. I would suggest only using one worker node and one master node to begin with and then increase them once you have confirmed the config is good. The more workers and master nodes you have, the longer it will take to run a rolling-update.
kops create cluster --cloud aws --name $CLUSTER_NAME --state s3://$K8SSTATE --node-count 1 --zones eu-west-1a,eu-west-1b,eu-west-1c --node-size t2.micro --master-size t2.micro --master-zoneseu-west-1a,eu-west-1b,eu-west-1c --ssh-public-key ~/.ssh/id_rsa.pub --topology=private --networking=weave --associate-public-ip=false --vpc $VPC
Important note: There must be an ODD number of master zones. If you tell kops to use an even number zones for master, it will complain.
If you want to use additional security groups, don’t add them yet – add them after you have confirmed the cluster is working.
Internal IPs: You must have a VPN connection into your VPC or you will not be able to ssh into the instances. The alternative is to use the bastion functionality using the –bastion flag with the create command. Then doing this:
ssh -i ~/.ssh/id_rsa -o ProxyCommand='ssh -W %h:%p admin@bastion.$CLUSTER_NAME' admin@INTERNAL_MASTER_IP
However, if you do this method, you MUST then use public IP addressing on the api load balancer, as you will not be able to do kops validate otherwise.
Edit the cluster
kops edit cluster $CLUSTER_NAME --state=s3://$K8SSTATE
Make the following changes:
If you have a VPN connection into the VPC, change spec.api.loadBalancer.type to “Internal”, otherwise, leave it as “Public”
Change spec.subnets to match your private subnets. To use existing private subnets, they should also include the id of the subnet and match the CIDR range, e.g.:
[code lang=text] subnets:
The utility subnet is where the Bastion hosts will be placed, and these should be in a public subnet, since they will be the inbound route into the cluster from the internet.
If you need to change or add specific IAM permissions, add them under spec.additionalPolicies like this to add additional policies to the node IAM policy (apologies about the formatting. WordPress is doing something weird to it.)
[code lang=text] additionalPolicies: node: | [ { “Effect”: “Allow”, “Action”: [“dynamodb:"], “Resource”: [""] }, { “Effect”: “Allow”, “Action”: [“es:"], “Resource”: [""] } ] [/code]
Edit the bastion, nodes, and master configs (MASTER_REGION is the zone where you placed the master. If you are running a multi-region master config, you’ll have to do this for each region)
kops edit ig master-{MASTER_REGION} --name=$CLUSTER_NAME --state s3://$K8SSTATE
kops edit ig nodes --name=$CLUSTER_NAME --state s3://$K8SSTATE
kops edit ig bastions --name=$CLUSTER_NAME --state s3://$K8SSTATE
Check and make any updates.
If you want a mixture of instance types (e.g. t2.mediums and r3.larges), you’ll need to separate these using new instance groups ($SUBNETS is the subnets where you want the nodes to appear – for example, you can provide a list “eu-west-2a,eu-west-2b)
kops create ig anothernodegroup --state s3://$K8SSTATE --subnets $SUBNETS
You can later delete this with
kops delete ig anothernodegroup --state s3://$K8SSTATE
If you want to use spot prices, add this under the spec section (x.xx is the price you want to bid):
maxPrice: "x.xx"
Check the instance size and count if you want to change them (I would recommend not changing the node count just yet)
If you want to add tags to the instances (for example for billing), add something like this to the spec section:
[code lang=text] cloudLabels: Billing: product-team</pre> [/code]
If you want to run some script(s) at node startup (cloud-init), add them to spec.additionalUserData:
[code lang=text] spec: additionalUserData:
Apply the update:
kops update cluster $CLUSTER_NAME --state s3://$K8SSTATE --yes
Wait for DNS to propagate and then validate
kops validate cluster --state s3://$K8SSTATE
Once the cluster returns ready, apply the Kubernetes dashboard
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/alternative/kubernetes-dashboard.yaml
Access the dashboard via
https://api.$CLUSTER_NAME/api/v1/namespaces/kube-system/services/kubernetes-dashboard/proxy/
also try:
https://api.$CLUSTER_NAME/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/
If the first doesn’t work
(ignore the cert error)
Username is “admin” and the password is found from your local ~/.kube/config
Add the External DNS update to allow you to give friendly names to your externally-exposed services rather than the horrible elb names.
See here: https://github.com/kubernetes-incubator/external-dns/blob/master/docs/tutorials/aws.md
(You can apply the yaml directly onto the cluster via the dashboard. Make sure you change the filter to match your domain or subdomain. )
Note that if you use this, you’ll need to change the node IAM policy on the cluster config as the default IAM policy won’t allow the External DNS container to modify Route 53 entries, and also annotate (use kubectl annotate $service_name key:value) your service with text such as:
external-dns.alpha.kubernetes.io/hostname: $SERVICE_NAME.$CLUSTERNAME
And also you might need this annotation, to make the ELB internal rather than public - otherwise Kubernetes will complain “Error creating load balancer (will retry): Failed to ensure load balancer for service namespace/service: could not find any suitable subnets for creating the ELB”
service.beta.kubernetes.io/aws-load-balancer-internal: 0.0.0.0/0
(Optional) Add the Cockpit pod to your cluster as described here
http://cockpit-project.org/guide/133/feature-kubernetes.html
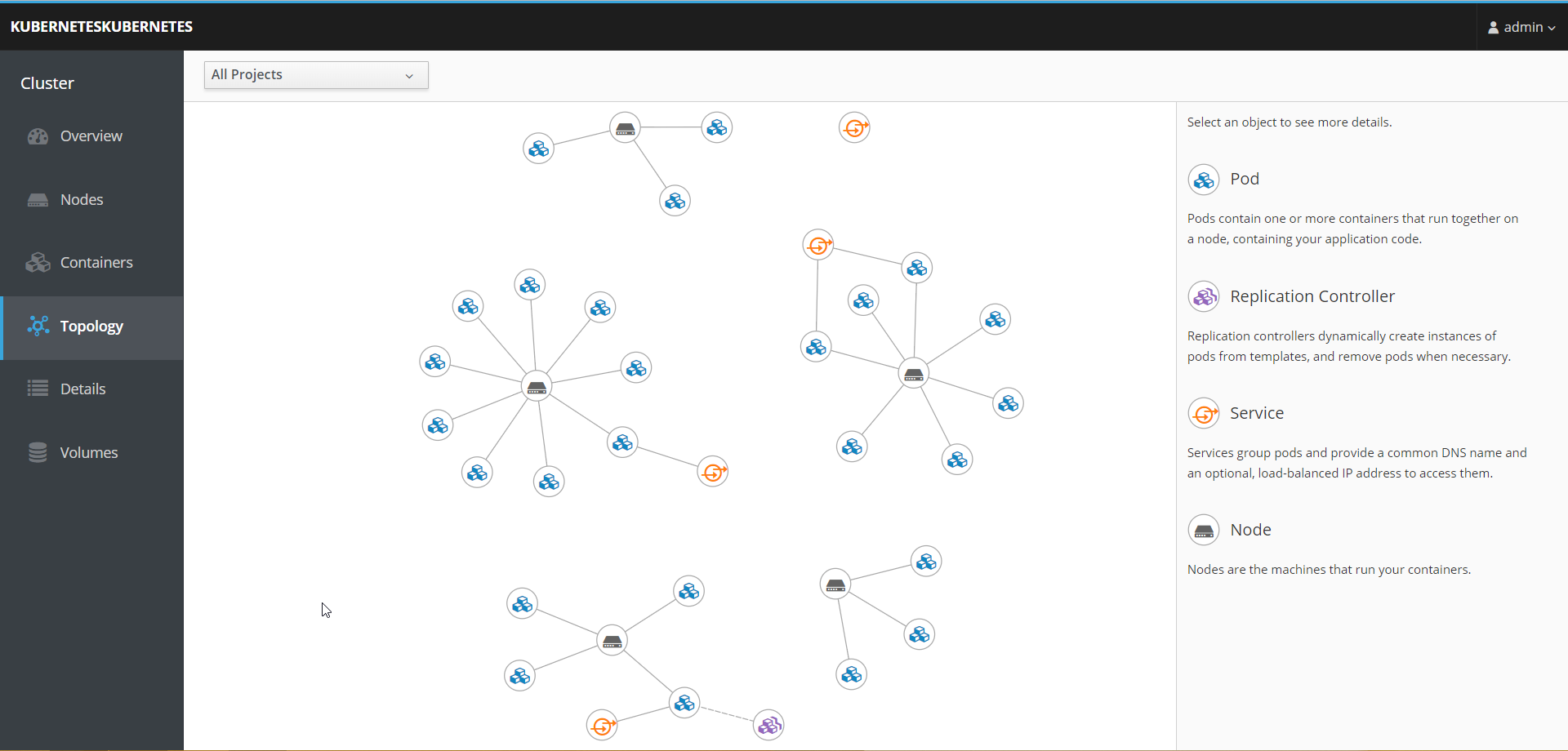
It will allow you to visually see a topology of your cluster at a cluster and also provides some management features too. For example, here’s my cluster. It contains 5 nodes (1 master, 4 workers and is running 4 services (Kubernetes, external-dns, cockpit, and dashboard). Cockpit creates a replication controller so it knows about the changes.
Add any additional security groups by adding this under the spec section of the node/master/bastions config, then do a rolling-update (you might need to use the –force switch), do this as soon as you can after creating and verifying the cluster updates work.
[code lang=text] additionalSecurityGroups:
If the cluster breaks after this (i.e. the nodes haven’t shown up on the master), reboot the server (don’t terminate, use the reboot option from the AWS console), and see if that helps. If it still doesn’t show up, there’s something wrong with the security groups attached – i.e. they’re conflicting somehow with the Kubernetes access. Remove those groups and then do another rolling-update but use both the –force and –cloudonly switches to force a “dirty” respin.
If the cluster comes up good, then you can change the node counts on the configs and apply the update.
Note that if you change the node count and then apply the update, the cluster attempts to make the update without rolling-update. For example, if you change the node count from 1 to 3, the cluster attempts to bring up the 2 additional nodes.
Other things you can look at:
Kompose - which converts a docker-compose configuration into Kubernetes resources
Finally, have fun!
An Intel flaw that has been sitting hidden for a decade has finally surfaced.
Being on the chip rather than the OS, it doesn’t affect a single OS – with Linux, Windows and MacOS being mentioned in this article.
This article just goes through my tinkering with Kubernetes on AWS.
Create a new S3 bucket to store the state of your Kubernetes clusters
aws s3 mb s3://k8sstate --region eu-west-2
Verify
aws s3 ls
Create a Route 53 hosted zone. I’m creating k8stest.blenderfox.uk
aws route53 create-hosted-zone --name k8stest.blenderfox.uk \ --caller-reference $(uuidgen)
dig the nameservers for the hosted zone you created
dig NS k8stest.blenderfox.uk
If your internet connection already has DNS setup to the hosted zone, you’ll see the nameservers in the output:
;; QUESTION SECTION: ;k8stest.blenderfox.uk. IN NS ;; ANSWER SECTION: k8stest.blenderfox.uk. 172800 IN NS ns-1353.awsdns-41.org. k8stest.blenderfox.uk. 172800 IN NS ns-1816.awsdns-35.co.uk. k8stest.blenderfox.uk. 172800 IN NS ns-404.awsdns-50.com. k8stest.blenderfox.uk. 172800 IN NS ns-644.awsdns-16.net.
Export your AWS credentials as environment variables (I’ve found Kubernetes doesn’t reliably pick up the credentials from the aws cli especially if you have multiple profiles
export AWS_ACCESS_KEY_ID='your key here' export AWS_SECRET_ACCESS_KEY='your secret access key here'
You can also add it to a bash script and source it.
Create the cluster using kops. Note that the master zones must have an odd count (1, 3, etc.) since eu-west-2 only has two zones (a and b), I have to have only one zone here
kops create cluster --cloud aws --name cluster.k8stest.blenderfox.uk \ --state s3://k8sstate --node-count 3 --zones eu-west-2a,eu-west-2b \ --node-size m4.large --master-size m4.large \ --master-zones eu-west-2a \ --ssh-public-key ~/.ssh/id_rsa.pub \ --master-volume-size 50 \ --node-volume-size 50 \ --topology private
You can also add the –kubernetes-version switch to specifically pick a Kubernetes version to include in the cluster. Recognised versions are shown at
https://github.com/kubernetes/kops/blob/master/channels/stable
TL;DL: Bands are:
Each with their own Debian image.
Assuming the create completed successfully, update the cluster so it pushes the update out to your cloud
kops update cluster cluster.k8stest.blenderfox.uk --yes \ --state s3://k8sstate
While the cluster starts up, all the new records will be set up with placeholder IPs.

NOTE: Kubernetes needs an externally resolvable DNS name. Basically, you need to be able to create a hosted zone on a domain you control. You can’t use Kops on a domain you can’t control, even if you hack the resolver config.
The cluster can take a while to come up. Use
kops validate cluster –state s3://k8sstate
To check the cluster state.
When ready, you’ll see something like this:
Using cluster from kubectl context: cluster.k8stest.blenderfox.co.uk Validating cluster cluster.k8stest.blenderfox.co.uk INSTANCE GROUPS NAME ROLE MACHINETYPE MIN MAX SUBNETS master-eu-west-2a Master m4.large 1 1 eu-west-2a nodes Node m4.large 3 3 eu-west-2a,eu-west-2b NODE STATUS NAME ROLE READY ip-172-20-35-51.eu-west-2.compute.internal master True ip-172-20-49-10.eu-west-2.compute.internal node True ip-172-20-72-100.eu-west-2.compute.internal node True ip-172-20-91-236.eu-west-2.compute.internal node True Your cluster cluster.k8stest.blenderfox.co.uk is ready
Now you can start interacting with the cluster. First thing is to deploy the Kubernetes dashboard
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/alternative/kubernetes-dashboard.yaml serviceaccount "kubernetes-dashboard" created role "kubernetes-dashboard-minimal" created rolebinding "kubernetes-dashboard-minimal" created deployment "kubernetes-dashboard" created service "kubernetes-dashboard" created
Now setup a proxy to the api
$ kubectl proxy Starting to serve on 127.0.0.1:8001
Next, access
http://localhost:8001/ui
To get the dashboard

Now let’s create a job to deploy on to the cluster.
Not often I quote from a publication from Ireland, but this was quite an intriguing read. Someone who went from Windows to Mac to Linux (Mint)
Linux is everywhere – and will free your computer from corporate clutchesIt was 2002, I was up against a deadline and a bullying software bubble popped up in Windows every few minutes. Unless I paid to upgrade my virus scanner – now! – terrible things would happen.
We’ve all had that right?
In a moment of clarity I realised that the virus scanner – and its developer’s aggressive business model – was more of a pest than any virus I’d encountered. Microsoft’s operating system was full of this kind of nonsense, so, ignoring snorts of derision from tech friends, I switched to the Apple universe.It was a great choice: a system that just worked, designed by a team that clearly put a lot of thought into stability and usability. Eventually the iPhone came along, and I was sucked in farther, marvelling at the simple elegance of life on Planet Apple and giving little thought to the consequences.
Then the dream developed cracks. My MacBook is 10 years old and technically fine, particularly since I replaced my knackered old hard drive with a fast new solid-state drive. So why the hourly demands to update my Apple operating system, an insistence that reminded of the Windows virus scanner of old?
Apple is no different to Microsoft it seems.
I don’t want to upgrade. My machine isn’t up to it, and I’m just fine as I am. But, like Microsoft, Apple has ways of making you upgrade. Why? Because, as a listed company, it has quarterly sales targets to meet. And users of older MacBooks like me are fair game.I looked at the price of a replacement MacBook but laughed at the idea of a midrange laptop giving me small change from €1,200. Two years after I de-Googled my life(iti.ms/2ASlrdY) I began my Apple prison break.
He eventually went for Linux Mint, which for a casual user is fine. I use Fedora and Ubuntu (and a really old version of Ubuntu since my workplace VPN doesn’t seem to work properly with anything above Ubuntu 14 - their way of forcing me onto either a Windows or Mac machine)
Source: www.irishtimes.com/business/…
My opinion of Apple and its practices has never been high. But this is just stupid.
Type in “1+2+3=” in an iOS 11 device’s calculator app, and you get 6 (correctly), but type it in quickly (as demonstrated in this video) and you get 24.
Sure, it’ll no doubt get patched soon and Apple will twist the incident to prove how fast they can push out updates compared to Android. But the point remains - how did such a bug make it past testing? And what OTHER, similarly stupid bugs that have yet to be detected, also make it past testing. And what if one of those bugs was in something fundamental? Something that breaks the functionality of the device? Something like the 1/1/1970 bug that would brick the device, or even the infamous “effective power” bug that would annoying reboot someone’s phone. Or even the famous crashsafari site that was only meant to crash safari but managed to crash the device too (originally, anyway).
OR, was there even ANY testing?